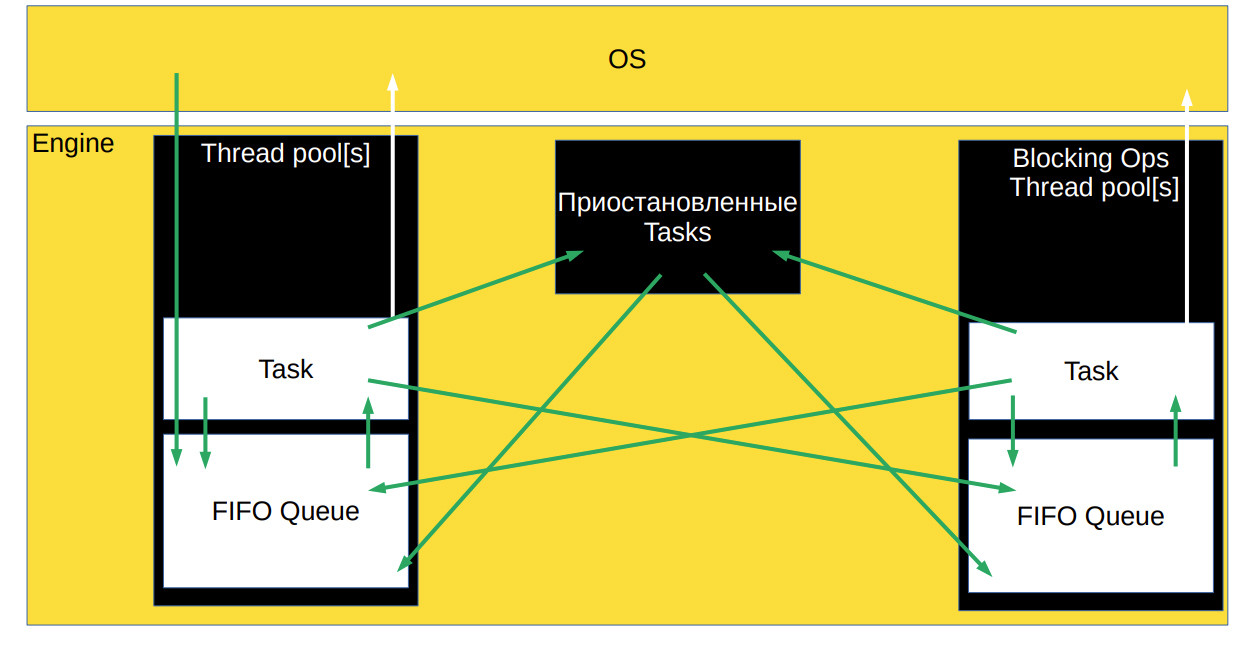
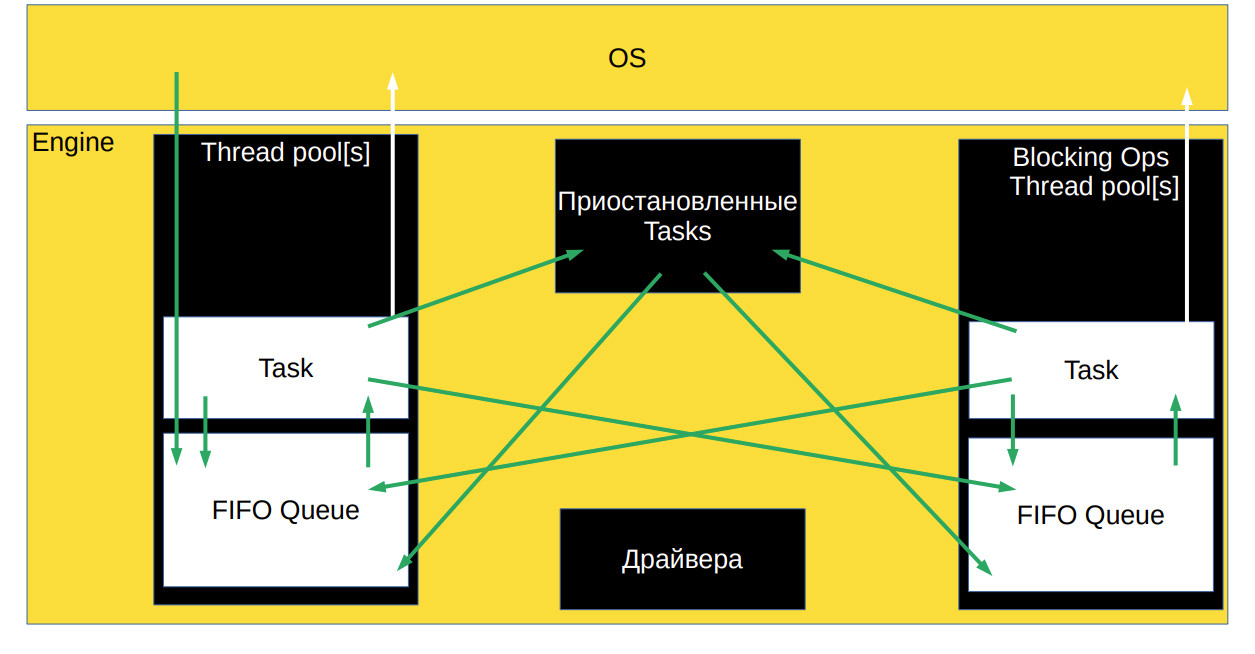
В этой статье вы узнаете об устройстве асинхронных движков с корутинами и без них. Для начала сосредоточимся не на конкретном движке, а на том, почему во всех популярных языках программирования появились корутины и чем они так хороши. Это может быть интересно не только C++-разработчикам, но и всем, кто занимается разработкой сетевых приложений или интересуется архитектурой современных фреймворков.
Пройдёмся по разным архитектурам построения серверов — от самой простой синхронной к более интересным, посмотрим на типичную архитектуру корутинового движка, а после окунёмся в дебри C++ и взглянем на самое страшное на примере нашего фреймворка userver.
Представьте, что у вашего сервиса очень маленькая нагрузка — 100 rps, и вам дали задачу написать простой сервер, понятный каждому второму школьнику. У вас получится что-то наподобие следующего:
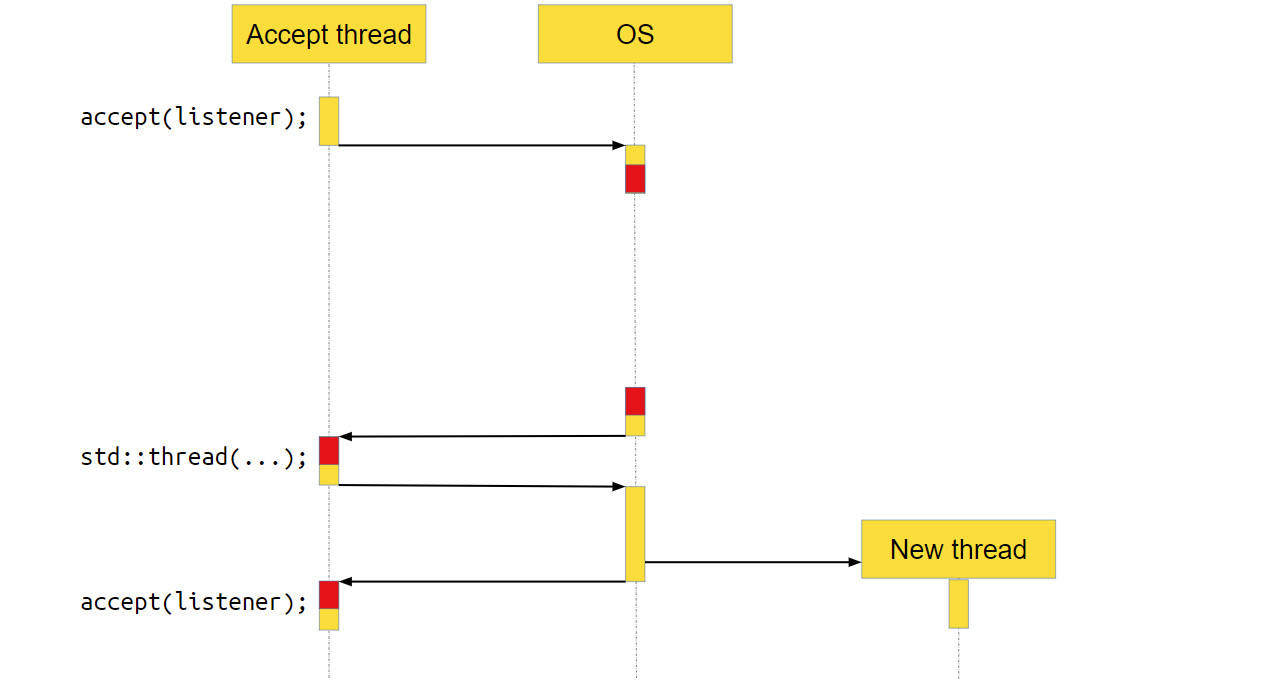
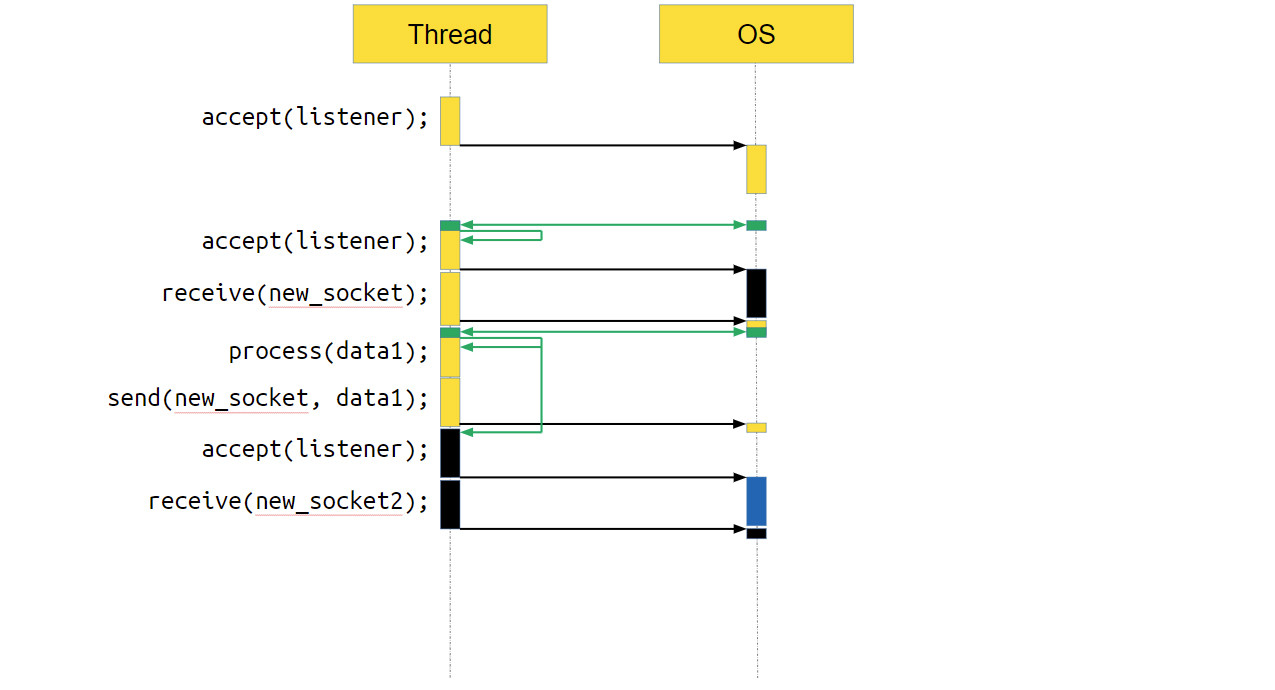
Сервер принимает новые соединения в бесконечном цикле с помощью функции accept. Как только у нас появляется новое соединение socket, мы передаём его в отдельный поток выполнения и уже в этом потоке с ним работаем. Мы считываем из socket’а данные, обрабатываем их и отправляем обратно по socket’у ответ. Всё очень просто. Как такой сервер выглядит для операционной системы (ОС)?
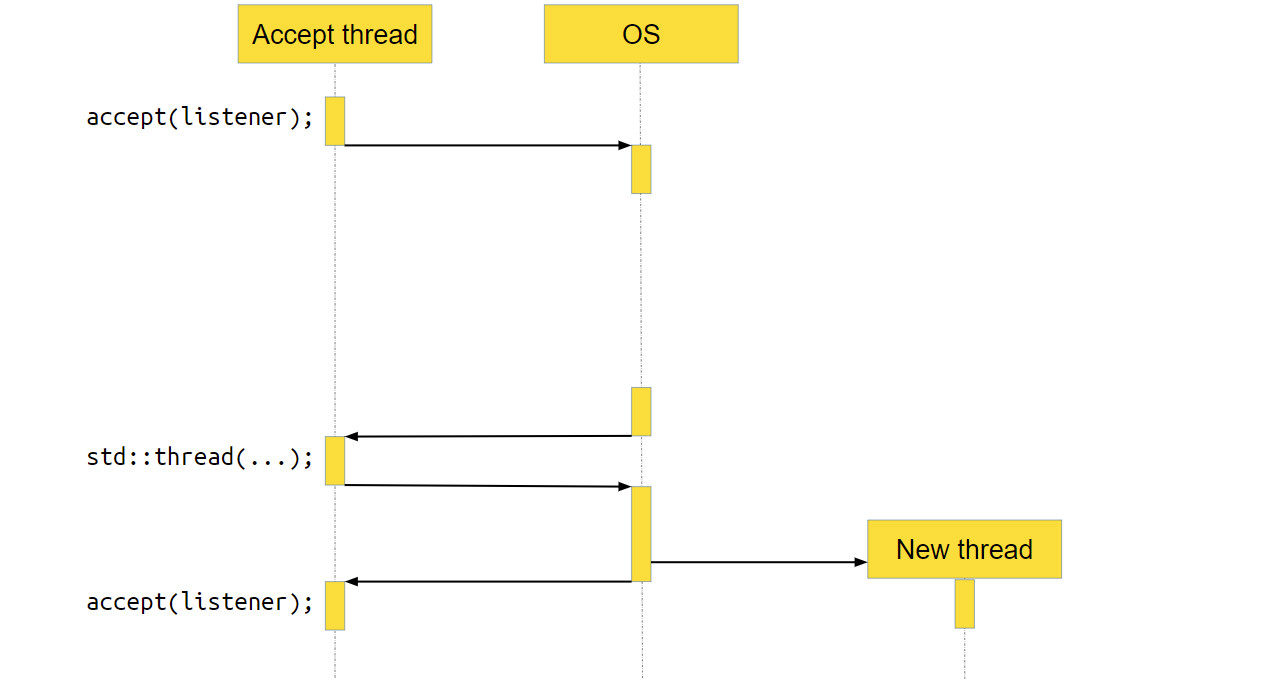
Мы вызываем accept. accept — это системный вызов, то есть функция, которая пойдёт в операционку, и уже операционка выполнит необходимые действия, в данном случае — вернёт новое соединение.
Но нового соединения может и не быть, если пользователи нашего серверного приложения ещё не сделали к нему запрос. В этом случае ОС приостановит приложение, переключит контекст на другое, и ядро процессора будет работать с другой программой.
В какой-то момент новое соединение появится, операционная система это заметит и вернёт нашему приложению управление. Программа продолжит работать как ни в чём не бывало.
Переходим к следующей строке кода. Там создаётся std∷thread, куда мы передаём socket. За вызовом std∷thread тоже находится системный вызов, достаточно тяжёлый на многих операционных системах. Мы получаем новый поток выполнения. После этого всё продолжается в бесконечном цикле: мы опять вызываем accept, идём в операционную систему, делаем системный вызов, а ОС приостанавливает наш поток.
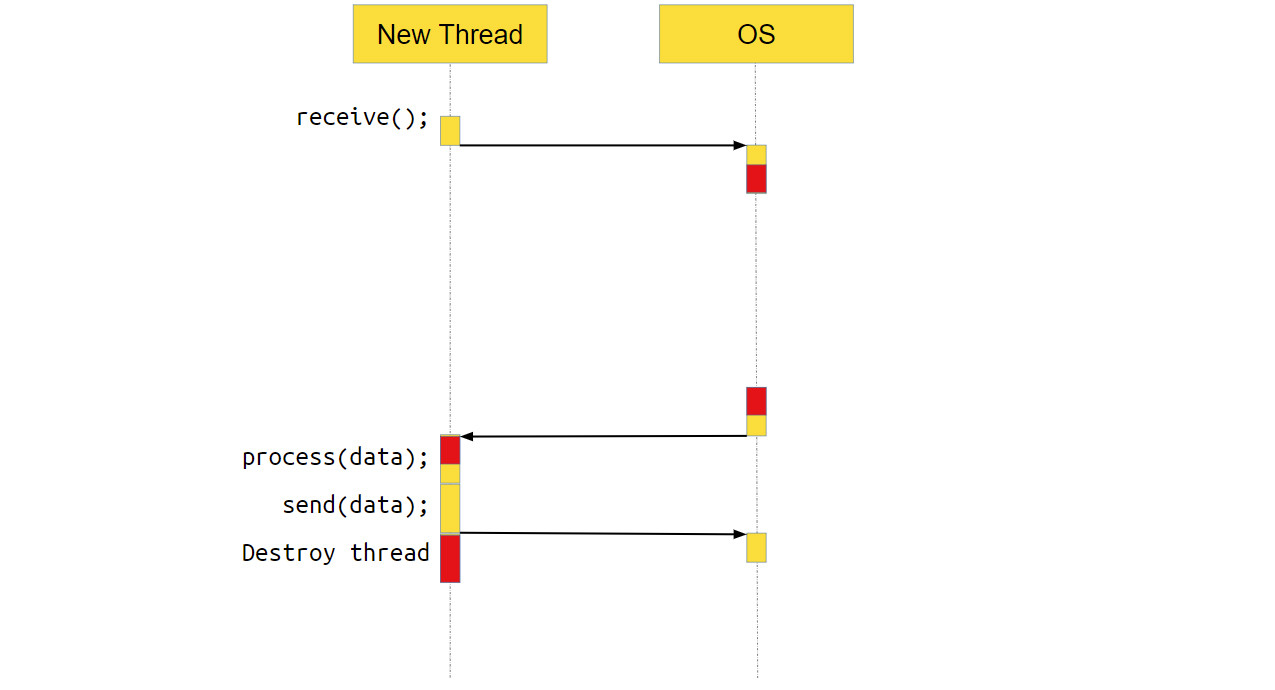
Что происходит с потоком, который получил новое соединение и обрабатывает его? В нём тоже выполняется системный вызов receive. То есть мы идём в систему, говорим: «Эй, операционка, дай нам данных! — а ОС отвечает, — Ой, на socket нет данных, пусть поток поспит, пока данные не появятся».
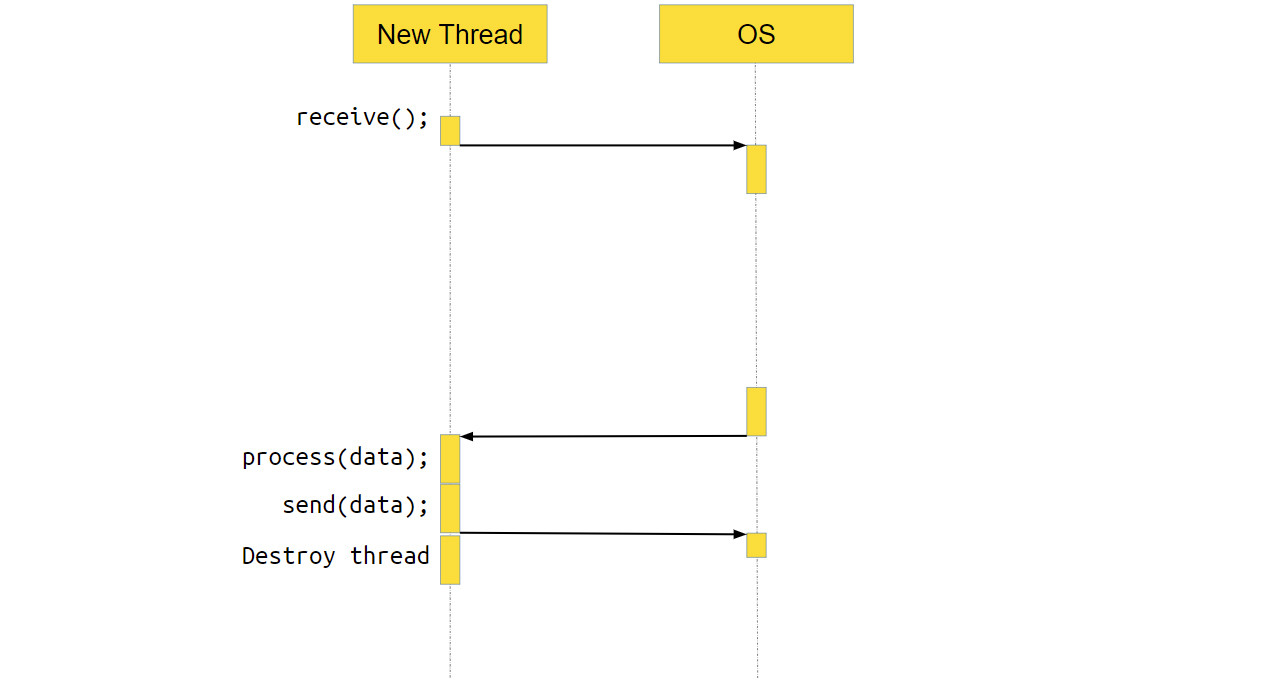
Когда данные появляются, ОС переключает выполнение обратно на наше приложение, оно обрабатывает данные и отправляет их через ОС по socket пользователю. После этого поток уничтожается — он своё дело сделал.
Плюсы описанного подхода очевидны — получается очень простой сервер. Его легко написать, легко читать, он понятный. Но есть и минусы, например, сервер весьма неэффективен, потому что мы делаем много тяжёлых операций, которых можно было не делать.
В табличке показано, сколько времени занимает та или иная операция:
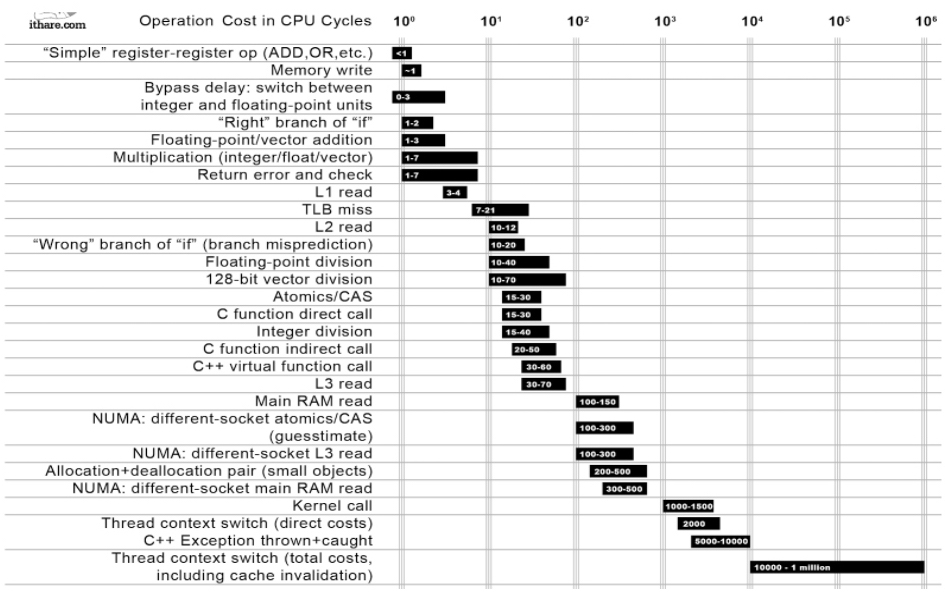
Самые «дешёвые» операции стоят наверху. Например, перемещение данных из регистра в регистр занимает меньше одного такта. А самые «дорогие» операции находятся внизу. И среди этих операций есть системный вызов, который занимает 1000–1500 тактов. А в самом-самом низу находится системный вызов, который приводит к переключению контекста. Такое переключение с возвратом обратно в приложение занимает от 10 тысяч тактов до миллиона.
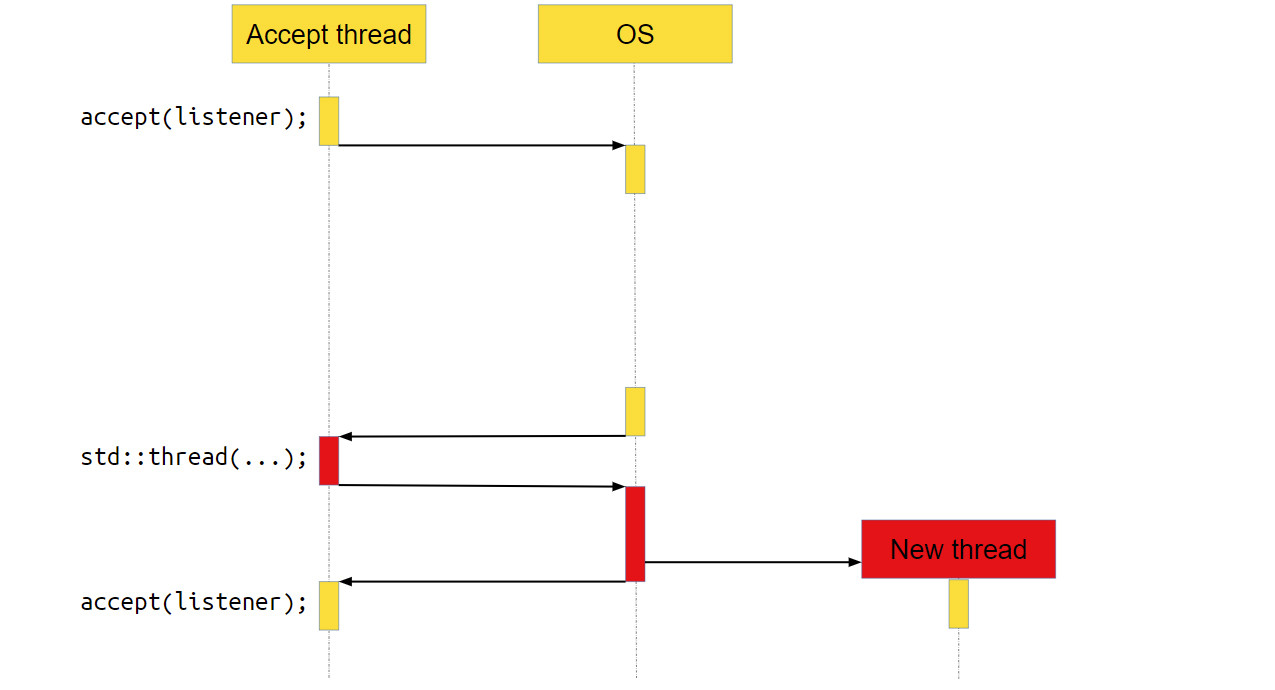
Если наше приложение занимается в основном тем, что получает данные и отправляет их куда-то, то есть является I/O bound приложением, количество переключений контекста может быть очень большим. Если от них избавиться, приложение станет работать в 10, 20, 30, а то и в 100 раз быстрее.
Другой недостаток этой архитектуры — то, что мы порождаем новый поток на каждый пользовательский запрос. Для некоторых приложений это может быть недопустимо. Например, приложения на Python, как правило, однопоточные. И создать в них новый поток — весьма своеобразная задача. Следовательно, для Python такая архитектура не подойдёт.
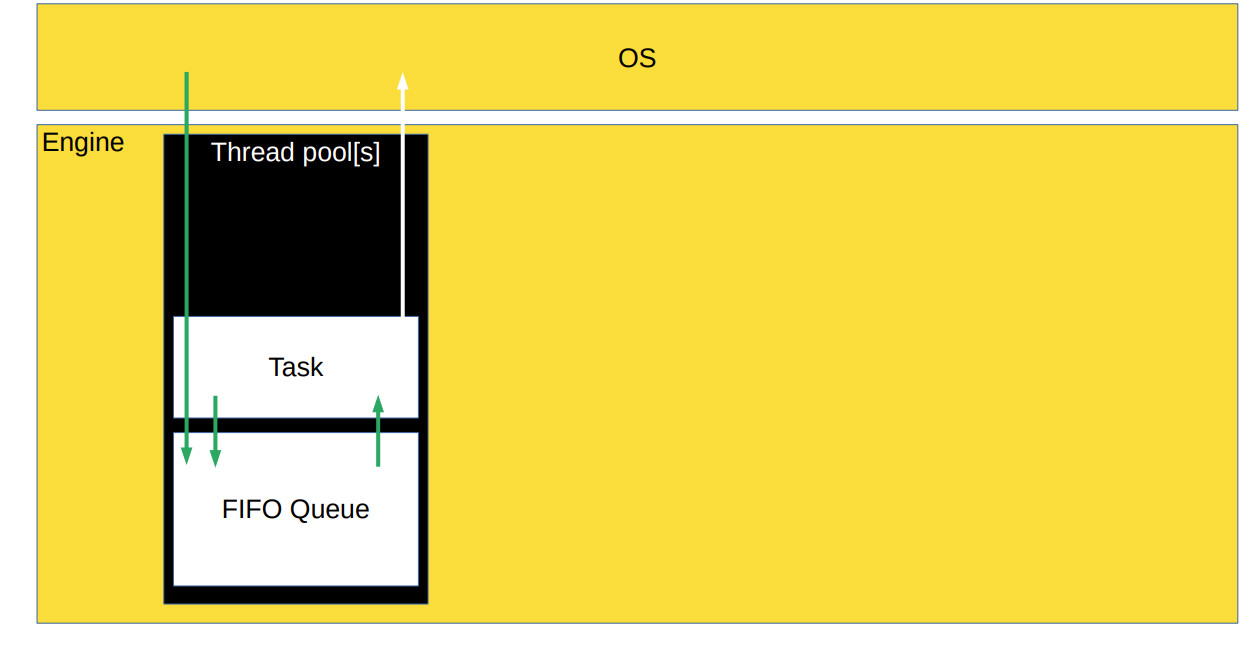
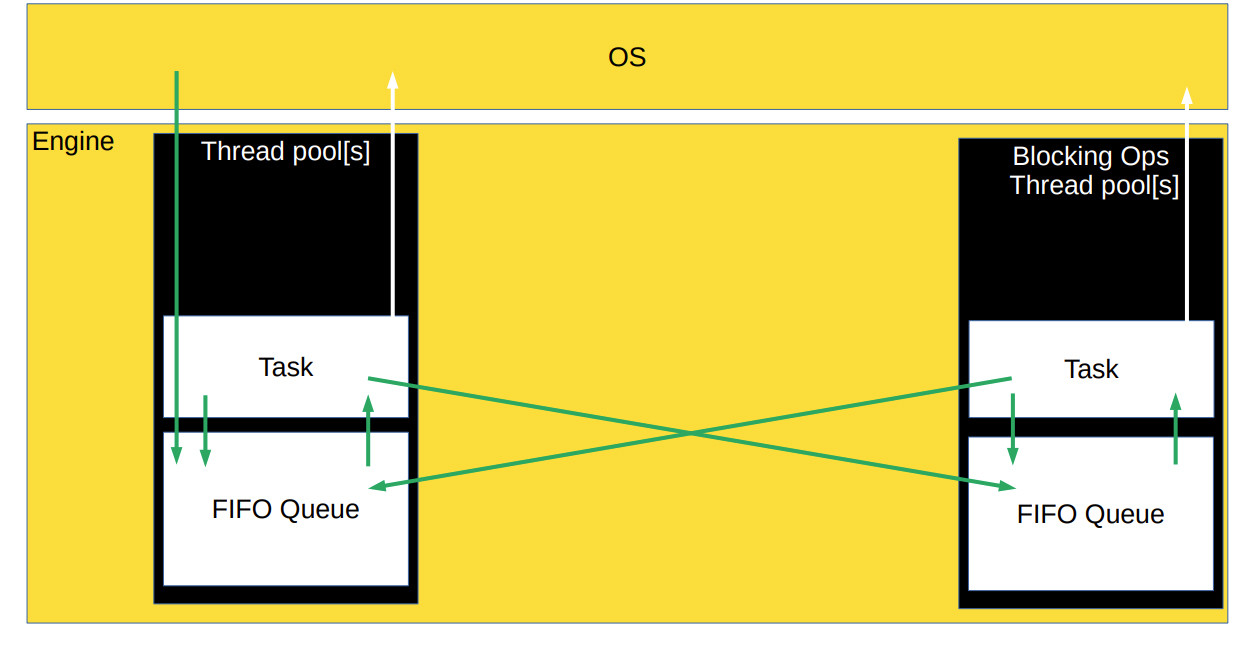
Создание потока — дорогая и тяжёлая операция. Если бы мы переиспользовали потоки, то получили бы дополнительный прирост производительности, а если бы работа шла в одном потоке, наша архитектура подходила бы для Python.
Пройдёмся по разным архитектурам построения серверов — от самой простой синхронной к более интересным, посмотрим на типичную архитектуру корутинового движка, а после окунёмся в дебри C++ и взглянем на самое страшное на примере нашего фреймворка userver.
Пишем синхронный сервер
Представьте, что у вашего сервиса очень маленькая нагрузка — 100 rps, и вам дали задачу написать простой сервер, понятный каждому второму школьнику. У вас получится что-то наподобие следующего:
Код:
void naive_accept() {
for (;;) {
auto new_socket = accept(listener);
std::thread thrd([socket = std::move(new_socket)] {
auto data = socket.receive();
process(data);
socket.send(data);
});
thrd.detach();
}
}Мы вызываем accept. accept — это системный вызов, то есть функция, которая пойдёт в операционку, и уже операционка выполнит необходимые действия, в данном случае — вернёт новое соединение.
Но нового соединения может и не быть, если пользователи нашего серверного приложения ещё не сделали к нему запрос. В этом случае ОС приостановит приложение, переключит контекст на другое, и ядро процессора будет работать с другой программой.
В какой-то момент новое соединение появится, операционная система это заметит и вернёт нашему приложению управление. Программа продолжит работать как ни в чём не бывало.
Переходим к следующей строке кода. Там создаётся std∷thread, куда мы передаём socket. За вызовом std∷thread тоже находится системный вызов, достаточно тяжёлый на многих операционных системах. Мы получаем новый поток выполнения. После этого всё продолжается в бесконечном цикле: мы опять вызываем accept, идём в операционную систему, делаем системный вызов, а ОС приостанавливает наш поток.
Что делает новый поток?
Что происходит с потоком, который получил новое соединение и обрабатывает его? В нём тоже выполняется системный вызов receive. То есть мы идём в систему, говорим: «Эй, операционка, дай нам данных! — а ОС отвечает, — Ой, на socket нет данных, пусть поток поспит, пока данные не появятся».
Когда данные появляются, ОС переключает выполнение обратно на наше приложение, оно обрабатывает данные и отправляет их через ОС по socket пользователю. После этого поток уничтожается — он своё дело сделал.
Плюсы и минусы наивного подхода
Плюсы описанного подхода очевидны — получается очень простой сервер. Его легко написать, легко читать, он понятный. Но есть и минусы, например, сервер весьма неэффективен, потому что мы делаем много тяжёлых операций, которых можно было не делать.
В табличке показано, сколько времени занимает та или иная операция:
Самые «дешёвые» операции стоят наверху. Например, перемещение данных из регистра в регистр занимает меньше одного такта. А самые «дорогие» операции находятся внизу. И среди этих операций есть системный вызов, который занимает 1000–1500 тактов. А в самом-самом низу находится системный вызов, который приводит к переключению контекста. Такое переключение с возвратом обратно в приложение занимает от 10 тысяч тактов до миллиона.
Если наше приложение занимается в основном тем, что получает данные и отправляет их куда-то, то есть является I/O bound приложением, количество переключений контекста может быть очень большим. Если от них избавиться, приложение станет работать в 10, 20, 30, а то и в 100 раз быстрее.
Другой недостаток этой архитектуры — то, что мы порождаем новый поток на каждый пользовательский запрос. Для некоторых приложений это может быть недопустимо. Например, приложения на Python, как правило, однопоточные. И создать в них новый поток — весьма своеобразная задача. Следовательно, для Python такая архитектура не подойдёт.
Создание потока — дорогая и тяжёлая операция. Если бы мы переиспользовали потоки, то получили бы дополнительный прирост производительности, а если бы работа шла в одном потоке, наша архитектура подходила бы для Python.
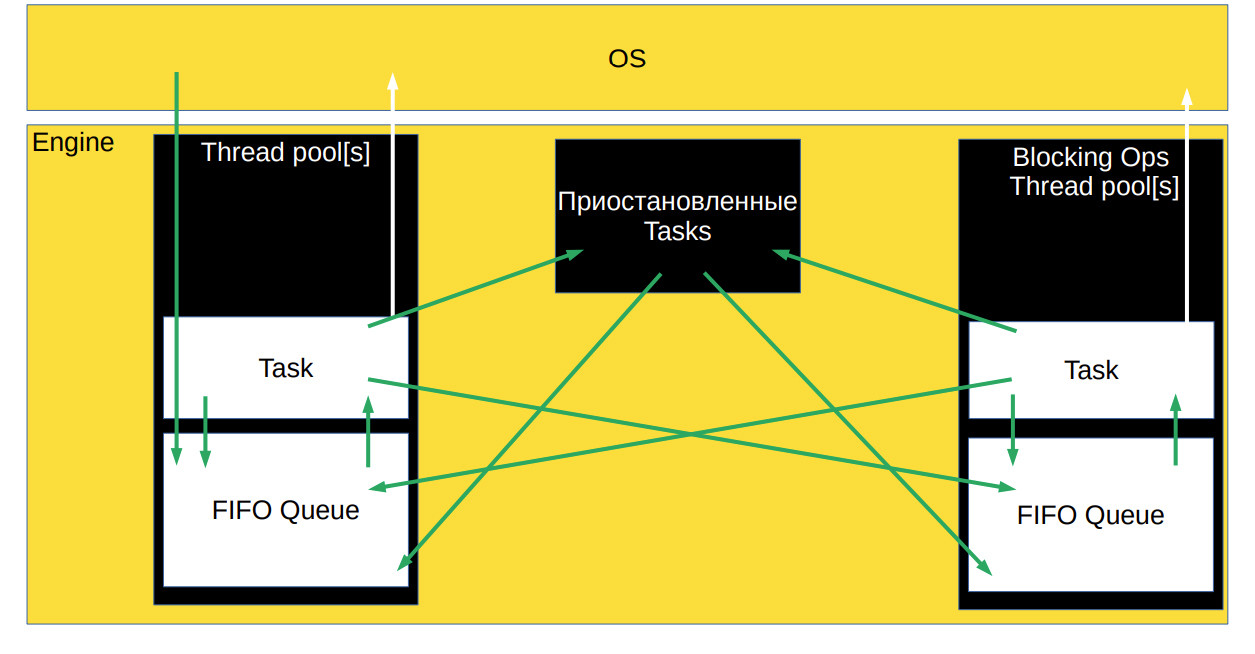
") {
{