
How to Speed Up Pandas with Modin
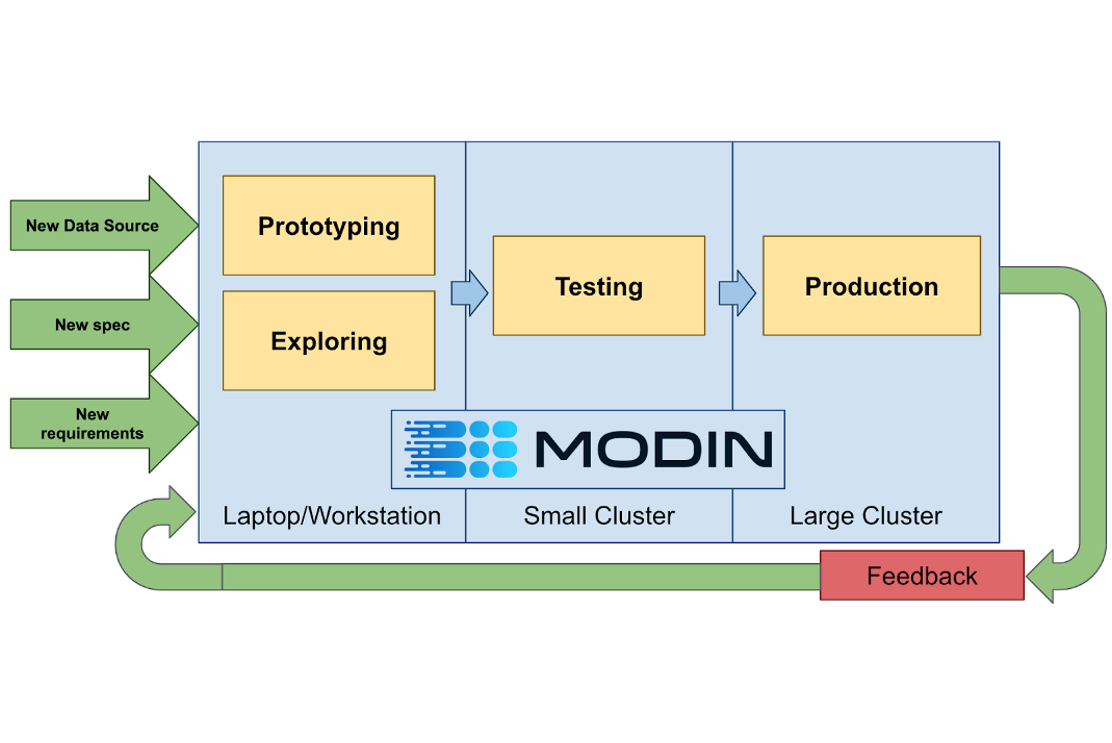
A goal of Modin is to allow data scientists to use the same code for small (kilobytes) and large datasets (terabytes). Image by Для просмотра ссылки Войдиили Зарегистрируйся.
The pandas library provides easy-to-use data structures like pandas DataFrames as well as tools for data analysis. One issue with pandas is that it can be slow with large amounts of data. ItДля просмотра ссылки Войдиили Зарегистрируйся. Fortunately, there is the Для просмотра ссылки Войди или Зарегистрируйся library which has benefits like the ability to scale your pandas workflows by changing one line of code and integration with the Python ecosystem and Ray clusters. This tutorial goes over how to get started with Modin and how it can speed up your pandas workflows.
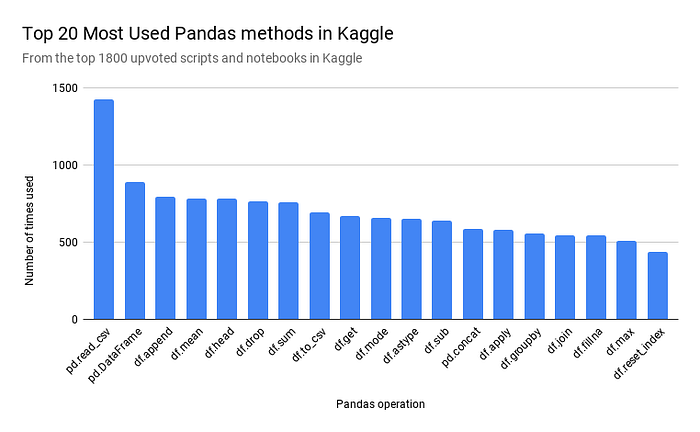
To determine which Pandas methods to implement in Modin first, the developers of Modin scraped 1800 of the most upvoted Python Kaggle Kernels (Для просмотра ссылки Войдиили Зарегистрируйся).
Modin’s coverage of the pandas API is over 90% with a focus on the most commonly used pandas methods like pd.read_csv, pd.DataFrame, df.fillna, and df.groupby. This means if you have a lot of data, you can perform most of the same operations as the pandas library faster. This section highlights some commonly used operations.
To get started, you need to install modin.
pip install “modin[all]” # Install Modin dependencies and modin’s execution engines
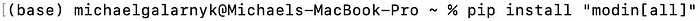
Don’t forgot the “” when pip installing
import modin.pandas as pd

You only need to change your import statement to use Modin.
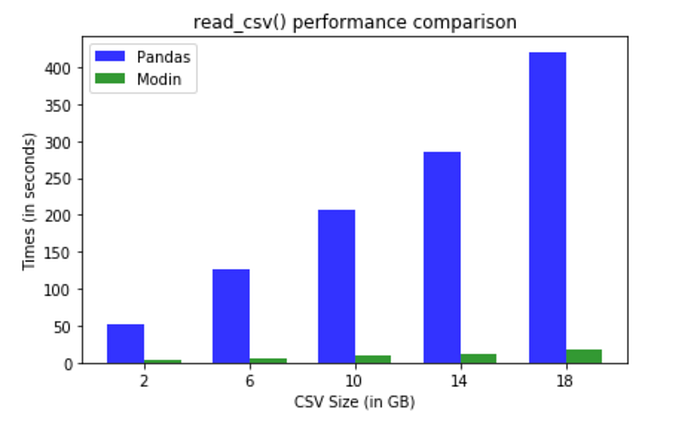
Modin really shines with larger datasets (Для просмотра ссылки Войдиили Зарегистрируйся)
The dataset used in this tutorial is from the Для просмотра ссылки Войдиили Зарегистрируйся dataset which is around 2GB .The code below reads the data into a Modin DataFrame.
modin_df = pd.read_csv("Rate.csv”)

In this case, Modin is faster due to it taking work off the main thread to be asynchronous. The file was read in-parallel. A large portion of the improvement was from building the DataFrame components asynchronously.
head
The code below utilizes the head command.
# Select top N number of records (default = 5)
modin_df.head()
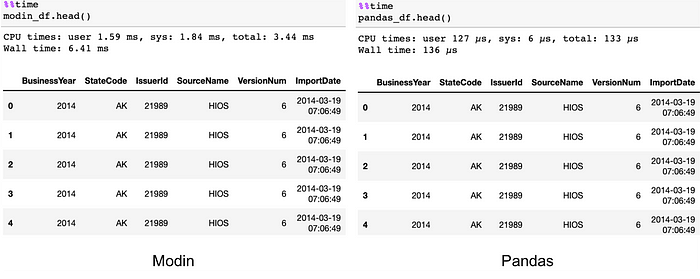
In this case, Modin is slower as it requires collecting the data together. However, users should not be able to perceive this difference in their interactive workflow.
groupby
Similar to pandas, modin has a groupby operation.
df.groupby(['StateCode’]).count()

Note that there are plans to further optimize the performance of groupby operations in Modin.
fillna
Filling in missing values with the fillna method can be much faster with Modin.
modin_df.fillna({‘IndividualTobaccoRate’: ‘Unknown’})

A goal of Modin is to allow data scientists to use the same code for small (kilobytes) and large datasets (terabytes). Image by Для просмотра ссылки Войди
The pandas library provides easy-to-use data structures like pandas DataFrames as well as tools for data analysis. One issue with pandas is that it can be slow with large amounts of data. ItДля просмотра ссылки Войди
How to get started with Modin
To determine which Pandas methods to implement in Modin first, the developers of Modin scraped 1800 of the most upvoted Python Kaggle Kernels (Для просмотра ссылки Войди
Modin’s coverage of the pandas API is over 90% with a focus on the most commonly used pandas methods like pd.read_csv, pd.DataFrame, df.fillna, and df.groupby. This means if you have a lot of data, you can perform most of the same operations as the pandas library faster. This section highlights some commonly used operations.
To get started, you need to install modin.
pip install “modin[all]” # Install Modin dependencies and modin’s execution engines
Don’t forgot the “” when pip installing
Import Modin
A major advantage of Modin is that it doesn’t require you to learn a new API. You only need to change your import statement.import modin.pandas as pd
You only need to change your import statement to use Modin.
Load data (read_csv)
Modin really shines with larger datasets (Для просмотра ссылки Войди
The dataset used in this tutorial is from the Для просмотра ссылки Войди
modin_df = pd.read_csv("Rate.csv”)
In this case, Modin is faster due to it taking work off the main thread to be asynchronous. The file was read in-parallel. A large portion of the improvement was from building the DataFrame components asynchronously.
head
The code below utilizes the head command.
# Select top N number of records (default = 5)
modin_df.head()
In this case, Modin is slower as it requires collecting the data together. However, users should not be able to perceive this difference in their interactive workflow.
groupby
Similar to pandas, modin has a groupby operation.
df.groupby(['StateCode’]).count()
Note that there are plans to further optimize the performance of groupby operations in Modin.
fillna
Filling in missing values with the fillna method can be much faster with Modin.
modin_df.fillna({‘IndividualTobaccoRate’: ‘Unknown’})