Часть 2: Binlogs
MySQL была спроектирована как база данных, которая может работать с различными движками (storage engines), поэтому MySQL можно разделить на два крупных “слоя” - непосредственно MySQL и различные Storage Engine (на практике это почти всегда InnoDB, реже Memory Engine, но изредка еще встречается MyISAM и MyRocksDB). Из-за этой “двухслойности” у нас есть и явное разделение обязанностей - MySQL занимается обработкой SQL запросов, репликацией (пишет binlogs), а InnoDB отвечает за надежное хранением данных на диске.
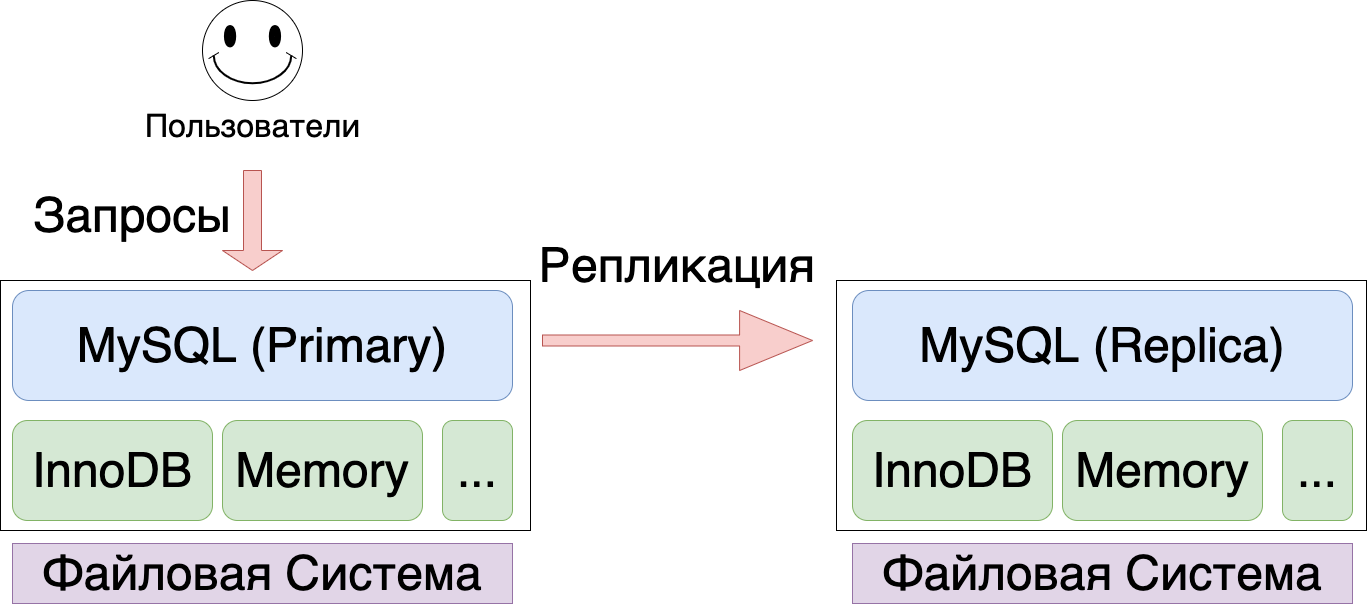
Для распространения изменений, записанных на мастере, MySQL использует подход Replicated State Machine (RSM)- все изменения записываются в binlog, и доставляются на реплики. Реплики применяют транзакции к своему текущему состоянию. Если транзакции полностью детерминированы - то в результате на мастере и на репликах получается одинаковое состояние (чего, собственно, мы и ожидаем от базы данных). Как побочный эффект детерминизма - к развернутой из бекапа базе данных можно проигрывать бинлоги и тем самым восстановить базу на любой момент времени (aka Point-in-Time Recovery).
MySQL может писать в binlog как SQL Statements (Statement-based replication), так и просто измененные данные (row-based replication). Для Statment-based replication сложнее гарантировать детерминированность транзакций и совпадение данных, хранящихся на разных хостах.
Binary Log в широком смысле слова - хранилище Binary Log Events (далее “события”). Эти события хранятся в binlog-файлах. Каждый файл начинается с заголовка, содержащего служебную информацию, потом идут события, и в конце пишется rotate event. Кроме этого, MySQL поддерживает Binlog Index, где хранится список всех имеющихся бинлогов.
Binlog cache
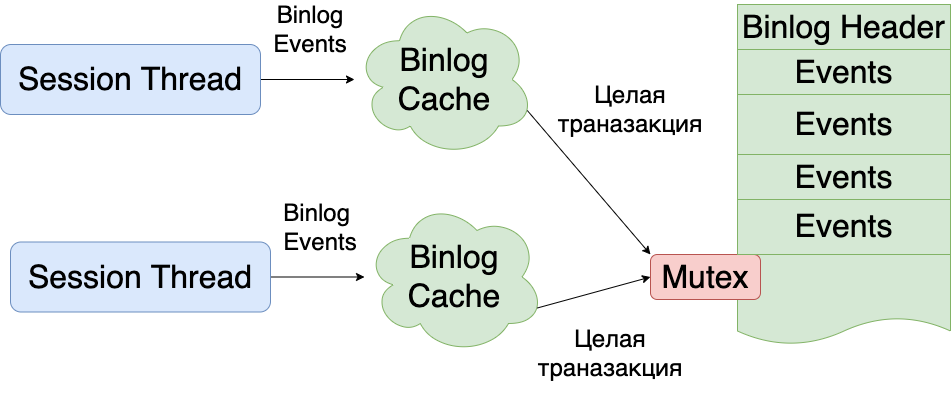
binlog — это файл, который пишется последовательно, целыми транзакциями. Пока одна транзакция не будет записана полностью, нельзя начинать писать вторую транзакцию. Для того, чтобы одни транзакции не блокировали запись других транзакций, все binlog events пишутся сначала в binlog cache (специальный буффер в памяти каждого потока, выполняющего транзакции) и только в момент коммита записываются уже на диск. В случае отката транзакции - binlog cache очищается, как будто ничего и не было записано в него.
Для просмотра ссылки Войди или Зарегистрируйся: Если
Для просмотра ссылки Войди или Зарегистрируйся было недостаточно, MySQL начнет сбрасывать кэш на диск (в новый файл, который сразу после создания будет удален (unlink) с файловой системы - т.е. будет “невидим”). Максимальный размер binlog cache на диске настраивается с помощью
Для просмотра ссылки Войди или Зарегистрируйся (по-умолчанию 18 эксабайт!). Хотя, документация говорит, что MySQL не может работать с бинлогами больше 4 Гб: при достижении этого порога будет выброшена ошибка.
Group Commit
Вооружившись знанием о том, что такое binlog, для crash-safe recovery необходимо делать fsync() на каждую запись в бинлоге (настройка sync_binlog = 1). Ведь, с одной стороны, binlog-и не участвуют в непосредственной записи наших данных на диск, используются в репликации (не очень связанной с хранением ваших данных на диске!) и вообще, бинлоги можно отключить, и база продолжит работать!
Если не скидывать бинлоги на диск - велик шанс что упавший MySQL после восстановления будет неконсистентен с другими репликами (и вам повезет, если вы это заметите сразу). В целом жить с sync_binlog отличном от 1
Для просмотра ссылки Войди или Зарегистрируйся, при условии отказа от crash-recovery и переналивкой упавших хостов. Вы же не ожидаете крэша всех хостов MySQL одной транзакцией или retry-ем одной транзакции по всем хостам
")
Допустим, мы все-таки хотим надежной записи на диск с помощью fsync. Как мы уже знаем, вызов fsync()-а это довольно медленная операция, где мы очень легко можем упереться в IOPS (особенно на HDD дисках). Очевидным решением бутылочного горлышка IOPS-ов является батчинг - на каждый fsync() писать не одну транзакцию, а сразу целую группу транзакций. В MySQL такой батчинг называется Group Commit.
Интересно, что MySQL 5.0 не делал Group Commit, и транзакции ожидали своей очереди для сохранения бинлога на диск. Ни о какой высокой производительности здесь речи идти не может.
В
Percona Server 5.5.18-23 Для просмотра ссылки Войди или Зарегистрируйся одну из первых версий group commit:
- Когда поток, выполняющий транзакцию, решит закоммитить транзакцию - он добавляет себя в group commit queue.
- После чего поток пытается понять - является ли он первым в group commit queue. Если он первый - то он становится “group commit leader”.
- Лидер Для просмотра ссылки Войди или Зарегистрируйся (Этот лок может быть занят предыдущим лидером, который все еще пишет на диск). Именно в это время другие потоки могут добавлять транзакции в group commit queue - тем самым собираясь в новую группу.
- Заполучив лок на весь бинлог, лидер Для просмотра ссылки Войди или Зарегистрируйся (следующий лидер создаст себе новую queue)
- Лидер записывает содержимое binlog cache каждого из потоков и делает fsync() (если надо). После чего он “Для просмотра ссылки Войди или Зарегистрируйся” пользовательские потоки, которые заблокировались на записи в бинлог.
Чуть позже, помимо группировки транзакций может быть настроен на небольшое ожидание перед записью в бинлог, пытаясь собрать побольше транзакций в group commit queue. По
Для просмотра ссылки Войди или Зарегистрируйся ребят из Percona - количество транзакций в секунду увеличивается на 30%.
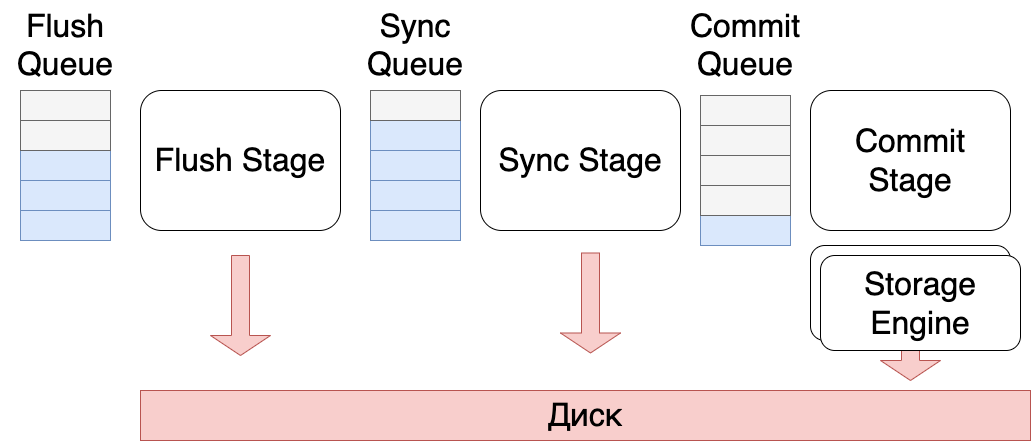
В актуальных версиях MySQL group commit сделан чуть по-другому: запись в бинлог разбита на этапы, которые управляются с помощью Commit_stage_manager. MySQL гарантирует, что порядок записи событий в бинлоге совпадает с порядком записи изменений в Storage Engines (Это значительно упрощает работу backup-тулам, таким как xtrabackup или MySQL Clone Plugin).
Все этапы (stages) образуют
Для просмотра ссылки Войди или Зарегистрируйся, в котором события берутся из очереди, обрабатываются и складываются в следующую очередь. Каждая очередь защищена своим мьютексом.
Всего используется
Для просмотра ссылки Войди или Зарегистрируйся:
- Binlog flush queue - очередь на запись на диск.
- Sync queue - очередь из транзакций, для которых надо вызвать fsync().
- Commit queue - очередь транзакций, которая используется для упорядочивания коммитов транзакций в пределах group commit. (необходима при binlog_order_commit=1).
- Commit order flush queue - очередь из транзакций, которые не пишут в бинлог, но участвуют в group commit - Для просмотра ссылки Войди или Зарегистрируйся для обновления gtid_executed в экзотических ситуациях.
Все stage работают по похожему алгоритму:
- Когда поток, выполняющий транзакцию, решит закоммитить транзакцию - он добавляет себя во flush queue.
- После чего поток пытается понять - является ли он первым в очереди или нет. Если он первый - то он становится stage leader.
- Stage Leader (после небольшого ожидания в binlog_max_flush_queue_time ms) забирает все транзакции из очереди и выполняет свою операцию
- binlog flush stage - производит Для просмотра ссылки Войди или Зарегистрируйся в бинлог: данные из binlog cache (binlog_cache_mngr) Для просмотра ссылки Войди или Зарегистрируйся в файл
- sync stage - Для просмотра ссылки Войди или Зарегистрируйся fsync()
- commit stage - транзакция коммитится в storage engine
- По завершению операции, Stage Leader добавляет транзакции, которыми он владел, в следующую очередь. Может так оказаться, что очередь, куда пишет stage leader не пуста - это означает что он Для просмотра ссылки Войди или Зарегистрируйся (который ожидает чего-то: блокировки или таймаута). В этот момент наш stage leader теряет свое лидерство. Его события будет обрабатывать “нагнанный” лидер. Такое поведение адаптирует размер group commit-а к самой медленной операции (обычно это fsync()) - долгие операции работают с бОльшим количеством event-ов за раз.
Параллельная репликация
Дополнительным преимуществом group commit является параллельная репликация - в пределах group-commit-а репликам позволено параллельно выполнять транзакции используя
Для просмотра ссылки Войди или Зарегистрируйся потоков, после чего они делают commit в том же порядке что и на мастере (
Для просмотра ссылки Войди или Зарегистрируйся), чтобы гарантировать что на реплике не будет состояния, которого никогда не было на мастере (Полезное свойство, если Вы читаете с реплик!).