metastrings - a CSV-driven NoSQL Database
Michael Sydney Balloni - 26/May/2020
Michael Sydney Balloni - 26/May/2020
[SHOWTOGROUPS=4,20]
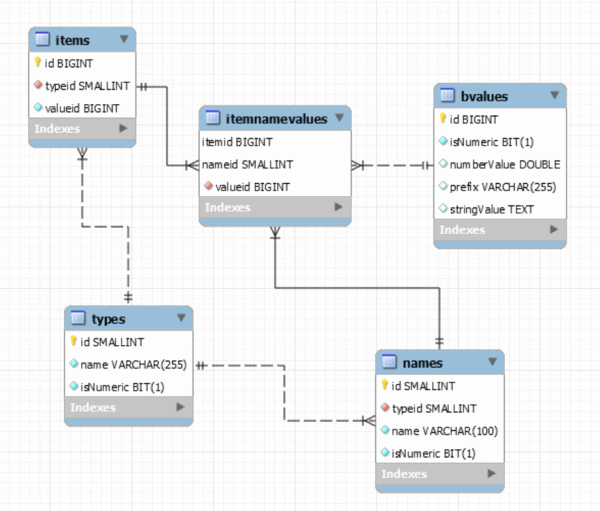
SQL schema and C# code for implementing a NoSQL database on top of MySQL
Database implementation and source code snippets, including a CSV appendix, tell the story of building a functional NoSQL database.
sources: https://dumpz.ws/resources/metastrings-a-csv-driven-nosql-database.113/
Introduction
I set out to create a CSV-driven NoSQL database powered by a SQL database with a completely normalized schema.
Values
All unique values in the database are represented in one table:
It's either a floating point number, or a string. If it's a string, it can be up to 64K characters long, UTF8 permitting.
The value "knows" if it's a number or a string with the isNumeric field.
An improvement over a previous incantation of this project is that small strings (<= 255 long) are not stored in the large text field at all. And the full-text index includes both the varchar and the text columns. So you get MATCH querying against something that can be small or large, and you only pay for the storage you use. If you want the string value, you'll see "IFNULL(stringValue, prefix)" around.
There are stored procedures to add / get IDs of values in the system:
Notice that I had to use "LIMIT 1" with the "SELECT LAST_INSERT_ID()" calls; not sure why, but it's been needed by others, and it was needed here.
Types (Think Table Names)
All type names are stored in a types table:
Names
All names of things (think column names) are stored in a names table:
Each name is associated with one type, and is inherently numeric or not.
Between types and names, the "table" schema is defined.
That rounds out the name-value universe for describing things. But what are we describing?
Items (Think Rows)
Each item has a type and an inherent value, think single-column primary key, like the path for a file system.
There is a stored procedure to add / get ID of items:
[/SHOWTOGROUPS]
SQL schema and C# code for implementing a NoSQL database on top of MySQL
Database implementation and source code snippets, including a CSV appendix, tell the story of building a functional NoSQL database.
sources: https://dumpz.ws/resources/metastrings-a-csv-driven-nosql-database.113/
Introduction
I set out to create a CSV-driven NoSQL database powered by a SQL database with a completely normalized schema.
Values
All unique values in the database are represented in one table:
Код:
CREATE TABLE `bvalues` (
`id` int NOT NULL AUTO_INCREMENT,
`isNumeric` bit(1) NOT NULL,
`numberValue` double DEFAULT NULL,
`prefix` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`stringValue` text CHARACTER SET utf8 COLLATE utf8_bin,
PRIMARY KEY (`id`),
KEY `idx_bvalues_prefix` (`prefix`,`isNumeric`,`id`),
KEY `idx_bvalues_number` (`numberValue`,`isNumeric`,`id`),
FULLTEXT KEY `idx_bvalues_prefix_stringValue` (`prefix`,`stringValue`)
)It's either a floating point number, or a string. If it's a string, it can be up to 64K characters long, UTF8 permitting.
The value "knows" if it's a number or a string with the isNumeric field.
An improvement over a previous incantation of this project is that small strings (<= 255 long) are not stored in the large text field at all. And the full-text index includes both the varchar and the text columns. So you get MATCH querying against something that can be small or large, and you only pay for the storage you use. If you want the string value, you'll see "IFNULL(stringValue, prefix)" around.
There are stored procedures to add / get IDs of values in the system:
Код:
; For working with numbers
CREATE DEFINER=`root`@`localhost` PROCEDURE `GetNumberId`(IN numberValueParam DOUBLE)
BEGIN
DECLARE valueId BIGINT DEFAULT NULL;
SELECT id INTO valueId
FROM bvalues
FORCE INDEX (idx_bvalues_number)
WHERE isNumeric = 1 AND numberValue = numberValueParam;
IF valueId IS NULL THEN
INSERT bvalues (isNumeric, numberValue) VALUES (1, numberValueParam);
SELECT LAST_INSERT_ID() INTO valueId LIMIT 1;
END IF;
SELECT valueId;
END
; For working with short strings
CREATE DEFINER=`root`@`localhost` _
PROCEDURE `GetShortStringId`(IN stringValueParam varchar(255))
BEGIN
DECLARE valueId BIGINT DEFAULT NULL;
SELECT id INTO valueId
FROM bvalues
FORCE INDEX (idx_bvalues_prefix)
WHERE isNumeric = 0 AND prefix = stringValueParam AND stringValue IS NULL;
IF valueId IS NULL THEN
INSERT bvalues (isNumeric, prefix, stringValue) VALUES (0, stringValueParam, NULL);
SELECT LAST_INSERT_ID() INTO valueId LIMIT 1;
END IF;
SELECT valueId;
END
; For working with long strings
CREATE DEFINER=`root`@`localhost` PROCEDURE `GetLongStringId`(IN stringValueParam TEXT)
BEGIN
DECLARE valueId BIGINT DEFAULT NULL;
DECLARE strPrefix VARCHAR(255) DEFAULT SUBSTRING(stringValueParam, 0, 255);
SELECT id INTO valueId FROM bvalues _
WHERE isNumeric = 0 AND prefix = strPrefix AND stringValue = stringValueParam;
IF valueId IS NULL THEN
INSERT bvalues (isNumeric, prefix, stringValue) VALUES (0, strPrefix, stringValueParam);
SELECT LAST_INSERT_ID() INTO valueId LIMIT 1;
END IF;
SELECT valueId;
ENDNotice that I had to use "LIMIT 1" with the "SELECT LAST_INSERT_ID()" calls; not sure why, but it's been needed by others, and it was needed here.
Types (Think Table Names)
All type names are stored in a types table:
Код:
CREATE TABLE `types` (
`id` smallint NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
`isNumeric` bit(1) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `name_UNIQUE` (`name`)
)Names
All names of things (think column names) are stored in a names table:
Код:
CREATE TABLE `names` (
`id` smallint NOT NULL AUTO_INCREMENT,
`typeid` smallint NOT NULL,
`name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
`isNumeric` bit(1) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `name_types` (`name`,`typeid`),
KEY `fk_name_types_idx` (`typeid`),
CONSTRAINT `fk_name_types` FOREIGN KEY (`typeid`) _
REFERENCES `types` (`id`) ON DELETE RESTRICT ON UPDATE RESTRICT
)Each name is associated with one type, and is inherently numeric or not.
Between types and names, the "table" schema is defined.
That rounds out the name-value universe for describing things. But what are we describing?
Items (Think Rows)
Код:
CREATE TABLE `items` (
`id` bigint NOT NULL AUTO_INCREMENT,
`typeid` smallint NOT NULL,
`valueid` int NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_items_valueid_typenameid` (`valueid`,`typeid`),
KEY `fk_item_typeid_idx` (`typeid`),
CONSTRAINT `fk_item_typeid` FOREIGN KEY (`typeid`) REFERENCES `types` (`id`),
CONSTRAINT `fk_item_valueid` FOREIGN KEY (`valueid`) _
REFERENCES `bvalues` (`id`) ON DELETE RESTRICT ON UPDATE RESTRICT
)Each item has a type and an inherent value, think single-column primary key, like the path for a file system.
There is a stored procedure to add / get ID of items:
Код:
CREATE DEFINER=`root`@`localhost` _
PROCEDURE `GetItemId`(IN typeIdParam INT, IN valueIdParam INT, IN noCreate BOOLEAN)
BEGIN
DECLARE itemId BIGINT DEFAULT NULL;
SELECT id INTO itemId
FROM items
WHERE typeId = typeidParam AND valueId = valueIdParam;
IF itemId IS NULL THEN
IF noCreate THEN
SELECT -1 INTO itemId;
ELSE
INSERT items (typeId, valueId)
VALUES (typeIdParam, valueIdParam);
SELECT LAST_INSERT_ID() INTO itemId LIMIT 1;
END IF;
END IF;
SELECT itemId;
END[/SHOWTOGROUPS]