Предположим, вы работаете в команде аналитики электронной коммерции в Amazon. Данные, с которыми вы имеете дело, огромны. В нем миллионы строк. Я буду использовать следующую гипотетическую таблицу под названием "продукт", содержащую 12 миллионов продуктов для всех демонстраций. (Интересный факт: Amazon продает более 12 миллионов товаров, не считая книг, медиа, вина и услуг.)
Рис.1 Таблица ‘продукт’ с 12 миллионами строк

Рис.2 4 примерные строки таблицы "продукт"
Давайте начнем с простого запроса.
Код:
ВЫБЕРИТЕ COUNT(*)
ИЗ product
, ГДЕ category = ‘электроника’;Можете ли вы сделать это быстрее? Да, вы можете.
Как? Путем индексирования.
Индексирование
Что такое индексирование?

Позвольте мне интуитивно объяснить всю концепцию индексации. Это называется "индексирование" из-за того, как индекс работает в книге. Если вы читаете книгу по статистике и хотите прочитать о "линейной регрессии", вам не захочется перелистывать сотни страниц одну за другой, чтобы добраться до главы, в которой говорится о "линейной регрессии".
Вместо этого вы откроете страницу индекса, найдете "линейная регрессия" и перейдете непосредственно на страницу.
Это метод, который базы данных используют с помощью индексации. Когда вы создаете индекс, база данных каким-то образом быстро находит данные, которые требуются запросу. Я расскажу об этом "как-нибудь" позже в статье.
Для просмотра ссылки Войди или Зарегистрируйся
Давайте создадим индекс в таблице "product" и включим в индекс "category".Синтаксис:
Код:
СОЗДАЙТЕ ИНДЕКС [имя_индекса]
ДЛЯ [имя_таблицы] ([имя_колонки]); Запрос:
СОЗДАЙТЕ ИНДЕКС product_category_index
ДЛЯ продукта (категории);Теперь давайте проверим производительность старого запроса с помощью индексации.
Код:
ВЫБЕРИТЕ COUNT(*)
ИЗ product
, ГДЕ category = ‘электроника’;Даже запросы, которые выходят за рамки использования "категории" в качестве условия, выиграют от индексации по "категории". Давайте посмотрим пример.
Код:
ВЫБЕРИТЕ COUNT(*)
ИЗ product
, ГДЕ category = ‘электроника'
И product_subcategory = ‘наушники’;Теперь давайте изменим порядок условий в предложении ‘WHERE’.
Код:
ВЫБЕРИТЕ COUNT(*)
ИЗ product
, ГДЕ product_subcategory = ‘наушники'
и category = ‘электроника’;Откуда он это знает?
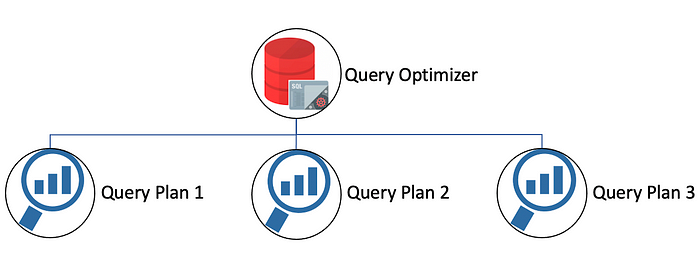
Рис.3 Возможные планы запросов для оптимизатора запросов (изображение автора)
База данных рассматривает все возможные пути выполнения запроса, а затем выбирает наиболее оптимальный путь.
Теперь пришло время для некоторого жаргона базы данных. Каждый из возможных путей называется ‘Для просмотра ссылки Войди
И эта функция СУБД, которая определяет наиболее эффективный способ выполнения данного запроса путем рассмотрения всех возможных планов запросов, называется "Для просмотра ссылки Войди
Последнее редактирование: