
One lovely London morning I was wandering around social media and noticed some activity about new Для просмотра ссылки Войди или Зарегистрируйся which will be part of Boost 1.80 release.
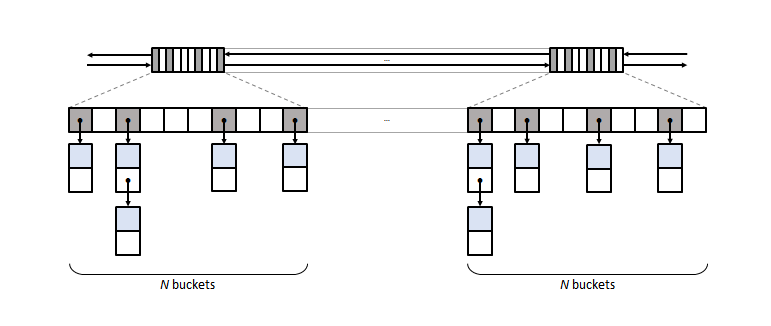
New bucket group layout used by boost::unordered_map 1.80
Why do I care? I’m CTO of Для просмотра ссылки Войдиили Зарегистрируйся and we’re one of the Для просмотра ссылки Войди или Зарегистрируйся products on market of DDoS detection and Для просмотра ссылки Войди или Зарегистрируйся make us fast.
I was well aware that hash arrays are quite complicated data structures as I’ve been working with them for around decade in a latency critical environment of network traffic processing.
I was prepared but I did not expected that they’re that complicated before dealing with some internal implementation details. I would recommend reading this Для просмотра ссылки Войдиили Зарегистрируйся to get understating why boost::unordered_map is great.
Performance evaluation of hash arrays can be done with variety of ways. Initially we had quite Для просмотра ссылки Войдиили Зарегистрируйся which filled hash array with sequence of 10m elements using 32 bit unsigned integers from 1 to 10m as keys and then tried to lookup them from 1 to 10m. Of course this test showed some numbers which can correlate with structure implementation but it had nothing to do with real lookup patterns of our application.
What is the proper way to test hash array? To test it properly you need to replicate your workload as close as possible.
In our case hash array keys are IPv4 addresses encoded as 32 bit unsigned big endian integers and value is a quite large 256 byte structure. What about lookup pattern? Can it be replicated in synthetic environment? Unfortunately, it will be very complicated as keys may be clustered and frequency of access to different keys will be very different. I’m pretty sure that it’s possible to build mathematical model to emulate this kind of distribution but it’s definitely above my level of mathematical education.
Let’s use traffic from real network. To run this data we’ve implemented Для просмотра ссылки Войдиили Зарегистрируйся app which just loads list of keys into memory and then hammers data structure with them from memory.
What about our data set? Is it good? It has list of IP addresses which belong to one quite large ISP. It has 131k unique IP addresses and 180k entries in total. We’ve recorded this traffic as it arrived to collector to emulate real traffic behaviour with our test.
That’s time to run tests. We’be decided to run tests using Boost 1.78 (it was stable version in our product), 1.79 (current latest version) and 1.80 (to be released in coming weeks).
To run tests I used one of our labs which has AMD Ryzen 5 3600 6-Core Processor with Ubuntu 16.04 LTS and uses gcc 12.1 (latest stable version available).
I decided to run tests for std::map, std::unorderd_map and boost::unorderd_map only.
Boost 1.78
Boost 1.79
или Зарегистрируйся hashing.
Boost 1.80
Conclusion
Data structures are crucial part of high performance applications. std::unordered_map is a great data structure but if you outgrow it then boost::unordered_map will be your best choice after Boost 1.80 release.
Thank you!
New bucket group layout used by boost::unordered_map 1.80
Why do I care? I’m CTO of Для просмотра ссылки Войди
I was well aware that hash arrays are quite complicated data structures as I’ve been working with them for around decade in a latency critical environment of network traffic processing.
I was prepared but I did not expected that they’re that complicated before dealing with some internal implementation details. I would recommend reading this Для просмотра ссылки Войди
Performance evaluation of hash arrays can be done with variety of ways. Initially we had quite Для просмотра ссылки Войди
What is the proper way to test hash array? To test it properly you need to replicate your workload as close as possible.
In our case hash array keys are IPv4 addresses encoded as 32 bit unsigned big endian integers and value is a quite large 256 byte structure. What about lookup pattern? Can it be replicated in synthetic environment? Unfortunately, it will be very complicated as keys may be clustered and frequency of access to different keys will be very different. I’m pretty sure that it’s possible to build mathematical model to emulate this kind of distribution but it’s definitely above my level of mathematical education.
Let’s use traffic from real network. To run this data we’ve implemented Для просмотра ссылки Войди
What about our data set? Is it good? It has list of IP addresses which belong to one quite large ISP. It has 131k unique IP addresses and 180k entries in total. We’ve recorded this traffic as it arrived to collector to emulate real traffic behaviour with our test.
That’s time to run tests. We’be decided to run tests using Boost 1.78 (it was stable version in our product), 1.79 (current latest version) and 1.80 (to be released in coming weeks).
To run tests I used one of our labs which has AMD Ryzen 5 3600 6-Core Processor with Ubuntu 16.04 LTS and uses gcc 12.1 (latest stable version available).
I decided to run tests for std::map, std::unorderd_map and boost::unorderd_map only.
Boost 1.78
- std::map: 3.09965 Millions operations per second
- std::unordered_map: 25.374 Millions operations per second
- boost::unordered_map: 19.9851 Millions operations per second
Boost 1.79
- std::map: 3.00941 Millions operations per second
- std::unordered_map: 25.3469 Millions operations per second
- boost::unordered_map: 15.9766 Millions operations per second
Boost 1.80
- std::map: 3.01219 Millions operations per second
- std::unordered_map: 25.2964 Millions operations per second
- boost::unordered_map: 32.3792 Millions operations per second
Conclusion
Data structures are crucial part of high performance applications. std::unordered_map is a great data structure but if you outgrow it then boost::unordered_map will be your best choice after Boost 1.80 release.
Thank you!